Diese Seite ist noch stark in Bearbeitung
Seit ich mich mit Graphen beschäftige, fehlt mir eine vernünftige Oberfläche zum Betrachten und Bearbeiten von Graphen. Hier meine Gedanken dazu, was ich gerne hätte.
Als Einführung ins Thema Graphen hat Christoph Pingel einen schönen Artikel geschrieben.
LPG und RDF
Beschreibung
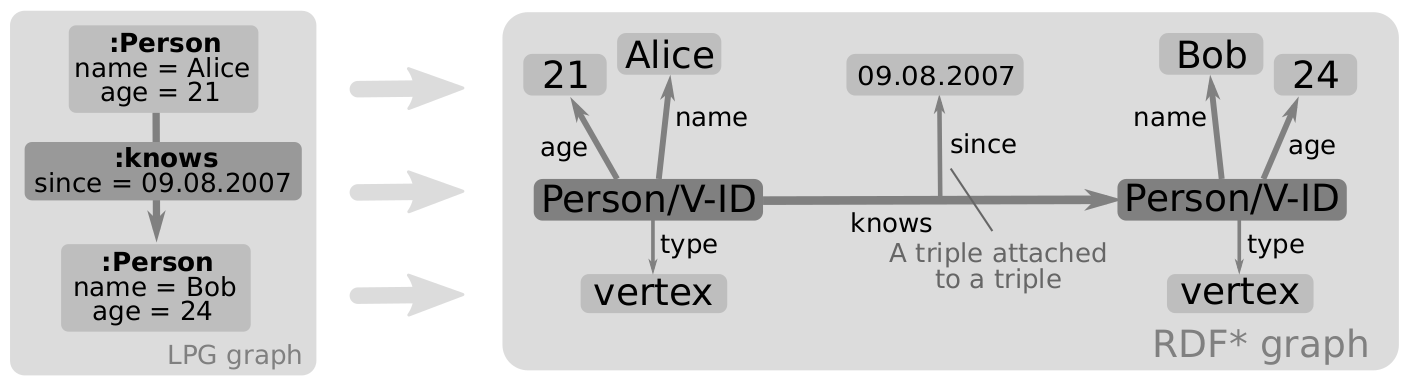
Zunächst zur Frage, über welches Graphmodell ich hier nachdenke. Im Wesentlichen gibt es zwei Modelle, die sich Ende 2022 durchgesetzt haben: RDF und Labeled Property Graph ( LPG).
 Quelle:
https://arxiv.org/abs/1910.09017
Quelle:
https://arxiv.org/abs/1910.09017
Bei RDF (rechts) gibt es im Kern Kennungen und Subjekt-Prädikat-Objekt Aussagen, die mit diesen Kennungen arbeiten:
@base <http://example.org/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix rel: <http://www.perceive.net/schemas/relationship/> .
<#123>
rel:friendOf <#456> ;
foaf:name "Alice" .Im Beispiel finden sich zwei Aussagen über die Kennung
http://example.org/123:
- Ein
http://www.perceive.net/schemas/relationship/friendOfvonhttp://example.org/456 - hat den String
Aliceals Wert fürhttp://xmlns.com/foaf/0.1/name
Auf diese Weise lassen sich sehr gut auch komplexe Aussagen über Kennungen / Knoten und ihre Beziehungen zueinander beschreiben. Zu merken ist, dass quasi alles bis auf direkte Werte Kennungen sind, die im Regelfall an entsprechender Stelle beschrieben sind, z.B. auf http://xmlns.com/foaf/0.1/.
Will man in herkömmlichem RDF Aussagen über Beziehungen treffen, geht man hierzu den Weg über “Reifikation”, d.h. man macht eine Beziehung selbst zu einer Art Knoten, über den dann wieder Aussagen getroffen werden. Um dieses zu Vereinfachen, gibt die Weiterentwicklung RDF* (RDF Star), in dem einfacher Aussagen über Beziehungen gemacht werden können (und welche im obigen Bild schon verwendet wird).
Vor- und Nachteile
Modellierung
Als Modell gefällt mir LPG erst mal gut (und besser als RDF), weil es einleuchtend einfach aussieht. Diese Einfachheit erlaubt einen einfachen Zugang für Anfänger oder Menschen, deren Rolle es nicht ist, Graphen in all ihrer Abstraktion zu verstehen.
Natürlich kann man auch in LPG auf den Gedanken kommen, statt Kanten “Beziehungsknoten” zu verwenden.
Hiermit ist aber schon der Pfad der Klarheit verlassen, und sowohl die Abfragen werden hässlich zu schreiben, als auch das Model wirklich schwierig zu verstehen.
Bleibt man bei der klaren Aufteilung von Knoten (mit Properties) und Kanten dazwischen (auch mit Properties), hat man eine klare Struktur, auf die man einfach das ganze mathematische Wissen um Graphen anwenden. Diesem Fakt ist vielleicht auch die große Zahl verfügbarer Algorithmen und Funktionen im Bereich LPG Graphdatenbanken zu verdanken.
Ein weiteres grundsätzliches Problem in RDF ist, dass die Subjekt-Prädikat-Objekt-Struktur zu kurz ist. Man möchte im zu jeder Aussage evtl. speichern, von wo sie kommt, oder ihr zumindest eine ID geben.
Daher gehe ich im Weiteren von LPG Graphen aus.
Schemata
Bei LPG kan man die Namen von Properties einfach vergeben. Ebenso einfach ist, dass Werte letztlich immer Skalare sind, also Strings, Integers etc. Man braucht sich um nichts weiter zu kümmern.
Man kann sich aber auch im Grunde um nichts kümmern: in LPG
Datenbanken gibt es zunächst keine Vorstellung von Namespaces, klar
definierten Eigenschaften, Relationen und ihr Verhältnis zueinander
(Ontologien). Weil hier nichts definiert wird, kann im Regelfall auch
nicht damit gearbeitet werden, wie es im Bereich RDF mit z.B. OWL
möglich ist. Dies ist nicht “schlimmer” als bei relationalen
Datenbanken, oder im Grunde weiten Teilen der Programmierung, führt aber
letztlich ins Chaos, wie im Buch The
Data Centric Revolution

schön von Dave McComb dargestellt wird. Chaos, weil auf
dieser Weise jede Anwendung mit ihrer jeweiligen Datenbank zu einer
kleinen Insel wird, weil die Bezeichner für Objekte und ihre Properties
nicht organisiert sind, und somit die Daten auch nicht “eben mal”
anwendungsübergreifend in Beziehung zueinander gebracht werden können.
(Ein aktueller Trend ist die Entwicklung von Metadaten-Katalogen, die
aber dann auch zur Ausbaustufe von Ontologien vorangetrieben werden
müssten.)
D.h., im Bereich LPG wäre es wünschenswert, mit genauer spezifizierten Relationen und Properties zu arbeiten, die idealerweise im Rahmen einer Ontologie definiert sind.
Was Schemata (wie z.B. SHACL bei RDF) angeht, gibt es zwar im LGP Bereich “contstraints”, mit denen vorgegeben werden kann, welche Eigenschaften Knoten haben müssen, die ein bestimmtes Label haben. Hieran gefällt mir aber nicht, dass damit der große Vorteil der Flexibilität in der Modellierung aufgegeben wird, im Grunde wird wieder ein starres Model wie in relationalen Datenbanken entwickelt. Es wird einem Knoten ein Label gegeben, und der Knoten ist dann korrekt, oder auch nicht. Ein Knoten kann somit nicht erst mal für sich stehen, und man kann dann frei schauen, welchen Schemata der Knoten entspricht.
Ich glaube, aber, dass man dies besser machen kann, und stelle die Idee im nächsten Abschnitt dar.
Wunschliste
Semantische Unterstützung
Python
In Python wird “Duck Typing” umgesetzt. D.h. anstatt zu fragen, ob
die Klasse eines Objekts von einer passenden Elternklasse abgeleitet
wird, kann man auch einfach schauen, ob passende Attribute und Methoden
auf einem Objekt vorhanden sind, und dann entsprechend damit arbeiten.
D.h., wenn ein Objekt die passenden Methoden hat, um es “iterable” zu
machen, kann
man es entsprechend einsetzen. Dieser Gedanke wird in Python mit typing.Protocol
fortgesetzt. Ein Protocol ist im Grunde ein Schema, welches die Struktur
eines Objektes beschreibt, und welches inzwischen auch zur Laufzeit
überprüft werden kann (runtime_checkable).
Sehe hierzu auch:
- https://www.informatik-aktuell.de/entwicklung/programmiersprachen/python-static-duck-typing.html
- https://peps.python.org/pep-0544/
Eigener Ansatz
Was ich gerne hätte, wäre ein System, in dem
- Properties
- Relationen
- Schemata/Label
beschrieben werden. Einen ersten Ansatz hierzu hatten Christoph Pingel und ich als selbstreferentielles Schema entwickelt. Hiermit kann eine Ontologie in einem LPG beschrieben werden.
Hat man eine Beschreibung der Bestandteile (Properties, Relationen, Schemata) des Graphen, kann man diese zum einen natürlich verwenden, um verschiedene Graphen zu verbinden, und auch innerhalb des Graphen logische Schlüsse zu ziehen (was aber erst noch entwickelt werden muss). Viel wichtiger ist aber die Unterstützung bei GUIs. Editiert man z.B. einen einzelnen Knoten, kann man so zu jedem (möglichen) Property und jeder möglichen Relation eine Erläuterung einblenden, was damit gemeint ist. Ebenso kann man relativ leicht überprüfen, welchen Schemata ein Knoten entspricht.
Editieren
Offensichtlich möchte ich endlich einen Editor haben, mit dem ich Knoten, Kanten und die Properties bearbeiten kann. Mir schwebt vor, dass ein (Wissens-)Graph nach und nach aufgebaut wird - irgendwie müssen die Informationen ja erst mal in den Graph hineinkommen. Natürlich ist dies nicht so notwendig, wenn “nur” Daten aus anderen Datenquellen in einem Graphen zusammengeführt werden.
Und beim Editieren sollte es die oben beschriebene semantische Unterstützung geben.
Abfrage
Natürlich möchte ich in einer Oberfläche den Graphen abfragen können. Primär sehe ich hier die eigene Abfragesprache der jeweiligen Graphdatenbank, also z.B. cypher. Für die Eingabekomponente stelle ich mir zumindest Syntax Highlighting und eine mit Pfeiltasten navigierbare History vor.
Ebenso wäre ein Query Builder GUI vorstellbar.
Ergebnismenge
Das Ergebnis der Abfrage soll dargestellt werden. Die mir bislang bekannten Tools gehen allerdings direkt von der Eingabe zur Darstellung über. Mir schwebt hingegen ein Zwischenschritt vor:
Der Zwischenschritt der Ergebnismenge erlaubt bei der Eingabe zu entscheiden, ob eine evtl. schon vorhandene Ergebnismenge:
- ersetzt
- erweitert
- reduziert
werden soll. Hierdurch kann man sich schrittweise einer gewünschten Darstellung annähern. Darüber hinaus können die Ergebnismengen auch zwischengespeichert werden (also die IDs von Knoten und Kanten). Hierdurch erhält man Views, die später wieder aufgerufen werden können. Hat man Ergebnismengen, hat man auch ideale Einstiegspunkte für eine mengenbasierte Navigation, wie sie David Huynh 2008 in Freebase Parallax vorstellt.
Views
Mengenansichten
Um eine Ergebnismenge anzuzeigen, sind mehrere Darstellungsformen interessant:
- Graphdarstellung 2D
- Graphdarstellung 3D
- Darstellung auf Karte
- Force Graph und andere Layout-Algorithmen
- Zeitstrahlen
Idealerweise kann der Nutzer zwischen diesen verschiedenen Ansichten wechseln, ohne die Ergebnismenge neu laden zu müssen.
Mindestens bei der Graphdarstellung 2D & 3D sollte es möglich
sein, die Position der Knoten zu verändern. Die Position sollte
speicherbar sein, sodass eine View später wieder aufgerufen werden kann,
hierzu müsste die Ergebnismenge (Ids) mitsamt der jeweiligen Positionen
zusammen gespeichert werden. Die Speicherung könnte natürlich in jeweils
einem eigenen “View” Knoten erfolgen, der entweder die Ids und
Positionen als Property hat, oder wir haben
View-[contains {pos: 1,2}]->Knoten Verbindungen.
Einzelansicht
Es braucht eine Graphdarstellung eines einzelnen Knotens. Diese sollte sowohl die Properties eines Knotens zugänglich machen, als auch die lokale Umgebung des Knotens darstellen, d.h. die verbundenen Knoten, ein oder mehrere Hops weit entfernt sind. Klickt man auf einen der Knoten, wird zur entsprechenden lokalen Ansicht gewechselt.
Eine Idee ist, dass wenn ein neuer Knoten ausgewählt wird, die alten Knoten noch im Bild bleiben, aber evtl. blasser werden. D.h. jeder Knoten bekommt eine Art ttl, die mit jedem Klick herabgezählt wird.
Ablage
Um mit mehreren Knoten arbeiten zu können, um z.B. Knoten zu vergleichen oder Werte hin und her zu kopieren wäre eine Art Ablage sinnvoll, in der man mehrere Knoten ablegen kann, und aus der heraus man auch wieder einen Knoten öffnen kann.
Open Source
Ich kann mir nicht vorstellen, einem Kunden ernsthaft closed-source Software für die Bearbeitung und Speicherung wichtiger Daten zu empfehlen, insbesondere nicht, wenn die Daten sicherheitsrelevant sind. Dementsprechend müsste die Bedienoberfläche auch Open Source sein. Natürlich stellt sich so die Frage nach dem Geschäftsmodell, aber vielleicht liese hier was mit Markenzeichen machen.
Implementierung
- Das ganze muss serverbasiert laufen zu können, um in weiteren Auslaufstufen auch eigene Sicherheitsmodelle unterstützen zu können. Ist die Anwendung eine reine JS Anwendung, müsste alle Sicherheit in der Datenbank stecken - eine für mich passende Annahme.
- Wenn die meiste Arbeit, inkl. Layout, auf dem Server passiert, kann man auch entsprechende Bibliotheken einsetzen, z.B. networkx.
- Dazu passen würde ich mir ein sehr schlankes Interaktionsframework vorstellen, natürlich fällt mir hier als erstes htmx ein.
- Wenn es eben geht, wäre für die Graphdarstellung WebGL schick, wegen der Performance.
Status Quo und Inspirationen
Neo4j Browser
https://neo4j.com/developer/neo4j-browser/
- Eingabebereich von Queries funktioniert gut
- Graphdarstellung ist deutlich zu langsam bei vielen Knoten
- Keine Editiermöglichkeit
Neo4j Bloom
https://neo4j.com/developer/neo4j-bloom/
- Bessere Performance
- Eingeschränkte Editiermöglichkeit
- Nicht alle Datentypen werden voll unterstützt
- Keine frei editierbaren Properties bei Kanten
- Keine freie Eingabe von Queries
- Keine semantische Unterstützung
- (Noch) keine Kartendarstellung
- Kein Open Source
NeoDash
https://neo4j.com/labs/neodash/
- Praktisch für eigene Dashboards
- Performt nicht sonderlich gut bei größeren Datenmengen
- Keine Editiermöglichkeiten
Parallax
- Super inspirierende Art und Weise, wie man in Mengen navigiert Das Konzept wird auch z.B. bei semspect umgesetzt.
- Braucht die Anbindung eines Editors
- Funktioniert nicht mehr
memgraph lab
- Bessere Performance bei größeren Graphen als neo4j browser
- Interessante Darstellungssprache GSS
- Nicht so gute Eingabe von Queries
- Keine Pfeiltasten-History
- Manchmal hakt das Syntax-Highlighting
- Closed Source
Die Visualisierungskomponente orb.js ist als Open Source erhältlich, was interessant für eine Weiterverwendung ist.
yworks
- Sehr schöne Layout-Algorithmen
- Closed Source
- Keine semantische Unterstützung beim Editieren
- Ist zum Editieren von Darstellungen gedacht, nicht für die Graphdatenbank selber